La interpolación consiste en hallar un dato de un intervalo en el que conocemos los valores en los extremos.
El problema general de la interpolación se nos presenta cuando se nos da n una función de la cual sólo conocemos una serie de puntos de la misma:
(X0,Y0), (X1,Y2), ….. (Xn,Yn).
Se pide hallar el valor de un punto x (intermedio de X0 y Xn) de esta función.
La interpolación se dará lineal cuando solo se tomen dos puntos y cuadrática cuando se tomen tres.
INTERPOLACIÓN LINEAL
Cuando las variaciones de la función son proporcionales (o casi proporcionales) a los de la variable independiente se puede admitir que dicha función es lineal y usar para estimar los valores de la interpolación lineal
Y- Y0 = (Y1-Y0)/(X1-Xo) (x – x0)
Sean dos puntos (X0 , Y0) (X1; Y2) la interpolación lineal consiste en hallar una estigmación del valor Y, para un valor X tal que X0 < X < X1.
Obtenemos la fórmula de la interpolación lineal
Y- Y0 = (Y1-Y0)/(X1-Xo) (x – x0)
INTERPOLACION CUADRATICA
Cuando el polinomio que conviene es de 2do grado la interpolación recibe el nombre de cuadrática. El polinomio interpolar es único, luego como se encuentre da igual, sin embargo, a veces los cálculos son muy laboriosos y es preferible utilizar un método que otro.
A la vista de los datos se decide.
En el ejemplo 1 se da el método de resolver el sistema para encontrar los valores que determinan a la función cuadrática (a, b y c)
También podemos utilizar la expresión del polinomio interpolado así:
Y= a+ b(x-x0) + c (x – x0) (x – x1), con la que la búsqueda de los coeficientes es muy sencilla.
LaGrange (1736 – 1813) dio una manera simplificada de calcular los polinomios interpolares de grado n, para el caso de un polinomio de 2do grado que pasas por esos puntos.
Que es la última fórmula de LaGrange para n = 2.
Ejemplo
Determinar la función lineal de interpolación que pasa por los puntos (-1,0), (4,2). Interpola el valor =1
Tenemos los puntos:
P (X0, Y0)= (-1,0)
Q (X1, Y1)= (4,2)
Tenemos los puntos:
P (X0, Y0)= (-1,0)
Q (X1, Y1)= (4,2)
Obtenemos la función de interpolación lineal:
F(x)=0+ (2-0)/(4-(-1)) (x-(-1))= 2/5 (x+1) = 2/5 x + 2/5
Interpolando a=1 obtenemos: f(1)= 2⁄5 + 2⁄5 = 4⁄5
Ejemplo
Calcula la recta que pasa por los puntos A (-3,2) y B (3,4). Interpola el valor de la función x=2
Hallamos la pendiente tomando, por ejemplo, los puntos A y B:
(X0, Y0)= A (-3, -2)
(X1, Y1)= B (3, 4)
(X0, Y0)= A (-3, -2)
(X1, Y1)= B (3, 4)
Obtenemos la función de interpolación lineal:
F(x)= -2+ (4-(-2))/(3-(-3)) (x-(-3))= -2+(x+3)=x+1
Interpolando x=2, obtendremos:
F (2)= 2+1=3
F(x)= -2+ (4-(-2))/(3-(-3)) (x-(-3))= -2+(x+3)=x+1
Interpolando x=2, obtendremos:
F (2)= 2+1=3
Ejemplo
Determinar la función cuadrática de interpolación que pasa por los puntos (0, -3), (1,0), (3, 0). Interpolar el valor a=2
Tenemos los puntos:
(X0, Y0)= (0, -3)
(X1, Y1)= (1, 0)
(X2, Y2)= (3,0)
(X0, Y0)= (0, -3)
(X1, Y1)= (1, 0)
(X2, Y2)= (3,0)
Resolvemos el sistema de ecuaciones:

Luego la función de interpolación es: y= -x^2+ 4x -3
Interpolando a=2, obtendremos: y= -2^2+4.2-3= 1
5.1 Polinomio de interpolación de Newton.
Es un método de interpolación polinómica. Aunque sólo existe un único polinomio que interpola una serie de puntos, existen diferentes formas de calcularlo. Este método es útil para situaciones que requieran un número bajo de puntos para interpolar, ya que a medida que crece el número de puntos, también lo hace el grado del polinomio.
Existen ciertas ventajas en el uso de este polinomio respecto al polinomio interpolador de Lagrange. Por ejemplo, si fuese necesario añadir algún nuevo punto o nodo a la función, tan sólo habría que calcular este último punto, dada la relación de recurrencia existente y demostrada anteriormente.
El primer paso para hallar la fórmula de la interpolación es definir la pendiente de orden de manera recursiva:

- : término i-ésimo de la secuencia



En general:
,

donde representa la distancia entre dos elementos (por ejemplo, se puede tener el elemento en y pero desconocer el valor de la secuencia en ).




Puede apreciarse cómo en la definición general se usa la pendiente del paso anterior, , a la cual se le resta la pendiente previa de mismo orden, es decir, el subíndice de los términos se decrementa en , como si se desplazara, para obtener .



Nótese también que aunque el término inicial siempre es , este puede ser en realidad cualquier otro, por ejemplo, se puede definir de manera análoga al caso mostrado arriba.


Una vez conocemos la pendiente, ya es posible definir el polinomio de grado de manera también recursiva:
- . Se define así ya que este valor es el único que se ajusta a la secuencia original para el primer término.
- .1
- .



En general:

5.2 Polinomio de interpolación de Lagrange.
En análisis numérico, el polinomio de Lagrange, llamado así en honor a Joseph-Louis de Lagrange, es una forma de presentar el polinomio que interpola un conjunto de puntos dado. Lagrange publicó este resultado en 1795, pero lo descubrió Edward Waring en 1779 y fue redescubierto más tarde por Leonhard Euler en 1783.1 Dado que existe un único polinomio interpolador para un determinado conjunto de puntos, resulta algo engañoso llamar a este polinomio el polinomio interpolador de Lagrange. Un nombre más apropiado es interpolación polinómica en la forma de Lagrange.
Un polinomio de interpolación de Lagrange, p, se define en la forma:
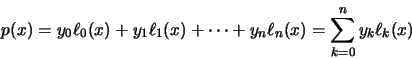
en donde 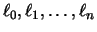 son polinomios que dependen sólo de los nodos tabulados
son polinomios que dependen sólo de los nodos tabulados 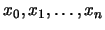 , pero no de las ordenadas
, pero no de las ordenadas  . La fórmula general del polinomio
. La fórmula general del polinomio 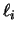 es:
es:
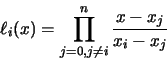
Para el conjunto de nodos , estos polinomios son conocidos como funciones cardinales. Utilizando estos polinomios en la ecuación (68) obtenemos la forma exacta del polinomio de interpolación de Lagrange.
Ejemplo: Suponga la siguiente tabla de datos:
| x | 5 | -7 | -6 | 0 |
| y | 1 | -23 | -54 | -954 |
Construya las funciones cardinales para el conjunto de nodos dado y el polinomio de interpolación de Lagrange correspondiente.
Las funciones cardinales, empleando la expresión (69), resultan ser:
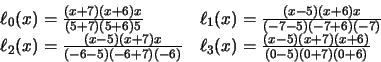
El polinomio de interpolación de Lagrange es:
5.3 Interpolación segmentada.
Esta interpolación se llama interpolación segmentaria o
interpolación por splines. La idea central es que en vez de usar un solo
polinomio para interpolar los datos, podemos usar segmentos de polinomios y
unirlos adecuadamente para formar nuestra interpolación.
Cabe mencionar que entre todas, las splines cúbicas han
resultado ser las más adecuadas para aplicaciones como la mencionada
anteriormente.
Así pues, podemos decir de manera informal, que una funcion
spline está formada por varios polinomios, cada uno definido en un intervalo y
que se unen entre si bajo ciertas
condiciones de continuidad.
Interpolación Segmentaria Lineal
Este es el caso más sencillo. En él, vamos a interpolar una
función f(x) de la que se nos dan un número N de pares (x,f(x)) por los que
tendrá que pasar nuestra función polinómica P(x). Esta serie de funciones
nuestras van a ser lineales, esto es, con grado 1: de la forma P(x) = ax + b.
Definiremos una de estas funciones por cada par de puntos
adyacentes, hasta un total de (N-1) funciones, haciéndolas pasar
obligatoriamente por los puntos que van a determinarlas, es decir, la función
P(x) será el conjunto de segmentos que unen nodos consecutivos; es por ello que
nuestra función será continua en dichos puntos, pero no derivable en general.
Interpolación Segmentaria Cuadrática
En este caso, los polinomios P(x) a través de los que
construimos el Spline tienen grado 2. Esto quiere decir, que va a tener la
forma P(x) = ax² + bx + c
Como en la interpolación segmentaria lineal, vamos a tener N-1 ecuaciones (donde N son los puntos sobre
los que se define la función). La interpolación cuadrática nos va a asegurar
que la función que nosotros generemos a trozos
con
los distintos P(x) va a ser continua, ya que para sacar las
condiciones que ajusten el polinomio, vamos a determinar como condiciones:
Que las partes de la función a trozos P(x) pasen por ese
punto. Es decir, que las dos Pn(x) que rodean al f(x) que queremos aproximar,
sean igual a f(x) en cada uno de estos puntos.
Que la derivada en un punto siempre coincida para ambos
"lados" de la función definida a trozos que pasa por tal punto común.
Esto sin embargo no es suficiente, y necesitamos una
condición más. ¿Por qué?. Tenemos 3 incógnitas por cada P(x). En un caso
sencillo con f(x) definida en tres puntos y dos ecuaciones P(x) para
aproximarla, vamos a tener seis incógnitas en total. Para resolver esto
necesitaríamos seis ecuaciones, pero vamos a tener tan sólo cinco: cuatro que
igualan el P(x) con el valor de f(x) en ese punto (dos por cada intervalo), y
la quinta al igualar la derivada en el punto común a las dos P(x).
Se necesita una sexta ecuación,¿de dónde se extrae? Esto
suele hacerse con el valor de la derivada en algún punto, al que se fuerza uno
de los P(x).
Interpolación Segmentaria Cúbica
En este caso, cada polinomio P(x) a través del que
construimos los Splines en [m,n] tiene grado 3. Esto quiere decir, que va a
tener la forma P(x) = ax³ + bx² + cx
+ d
En este caso vamos a tener cuatro variables por cada
intervalo (a,b,c,d), y una nueva condición para cada punto común a dos
intervalos, respecto a la derivada segunda:
Que las partes de la función a trozos P(x) pasen por ese
punto. Es decir, que las dos Pn(x) que rodean al f(x) que queremos aproximar,
sean igual a f(x) en cada uno de estos puntos.
Que la derivada en un punto siempre coincida para ambos
"lados" de la función definida a trozos que pasa por tal punto común.
Que la derivada segunda en un punto siempre coincida para
ambos "lados" de la función definida a trozos que pasa por tal punto
común.
Como puede deducirse al compararlo con el caso de splines
cuadráticos, ahora no nos va a faltar una sino dos ecuaciones (condiciones)
para el número de incógnitas que tenemos.
La forma de solucionar esto, determina el carácter de los
splines cúbicos. Así, podemos usar:
Splines cúbicos naturales: La forma más típica. La derivada
segunda de P se hace 0 para el primer y último punto sobre el que está definido
el conjunto de Splines, esto son, los puntos m y n en el intervalo [m,n].
Dar los valores de la derivada segunda de m y n de forma
"manual", en el conjunto de splines definidos en el intervalo [m,n].
Hacer iguales los valores de la derivada segunda de m y n
en el conjunto de splines definidos en el intervalo [m,n].
5.4 Regresión y correlación
Partimos de una distribución bidimensional (Xi Yj, nij) en la que
vamos a seguir avanzando estudiando las relaciones entre X
e Y→ nos movemos en el
campo de la dependencia estadística entre las variables. Para continuar el
estudio nos encontramos con el problema del AJUSTE: nos enfrentamos a una “nube
de puntos” dada por la representación
gráfica en unos ejes de coordenadas de los pares de valores de las 2 variable y
buscamos la ecuación que mejor se adapte al conjunto de puntos (obtención de la
ecuación de una curva que pase cerca de los puntos dados), imponiéndole
determinadas condiciones.
Por
tanto en el ajuste habrá dos fases:
1.- Seleccionar el tipo de función que mejor se adapte
–gráficamente- al conjunto de datos disponibles, es decir, que mejor represente la relación entre X e Y. La información es la nube de puntos→
útil la representación como primera orientación.
2.- Fijado el tipo de función, a través de su ecuación con
un cierto número de parámetros, determinar cuál de las funciones que hay en el
plano se adapta mejor al conjunto de puntos (que mejor se ajuste a la nube de
puntos de la función).
La determinación de la mejor curva (búsqueda
de los parámetros) se consigue
imponiendo una serie de
condiciones. Según cuáles sean estas condiciones de búsqueda, tendremos uno de
los distintos métodos de ajuste existentes.
El principal método
de ajuste utilizado
(y único que veremos) es el método
de NEYMAN o de
los MÍNIMOS CUADRADOS.
MÉTODO
DE LOS MÍNIMOS CUADRADOS.
De nuestra
distribución bidimensional (Xi Yj, nij) representada en una nube de puntos→ dados los puntos (X1 Y1), (X2 Y2)…. (Xi Yj)…. (Xh Yk), se elige una determinada función
de ajuste dada por la expresión siguiente: Y = f(X,
a1, a2, … , an) en la que
intervienen n parámetros.

Considerando la nube
de puntos, al ajustar una función, para cada valor de X=Xi tendremos dos valores de Y:
·
El
valor observado Yj correspondiente a la nube de
puntos (Xi Yj)
·
El
valor teórico Ytj resultado de hacer
X=Xi en la función :Ytj = f(Xi;a1…an)
= Yj*
Por tanto,
para cada Xi, tendremos la diferencia entre los 2 valores de Y Yj y Ytj, que llamamos
RESIDUO = ej→ej = Yj-Ytj (diferencia
entre Y observado y teórico).
El método
de los mínimos cuadrados consiste
en la determinación numérica de los parámetros (a1…an) de tal
manera que los residuos sean mínimos.
min ∑∑ (Yj – Ytj) nij = min ej
Si tomamos la suma de todos los residuos, se nos presenta
el inconveniente de que unos residuos serán de signo positivo y
otros de signo negativo, con lo que residuos de distinto signo al sumar se
pueden compensar y la suma mínima podría ocultar residuos de cierta importancia
a ambos lados de la curva ajustada. Para evitar que los residuos se anulen
entre sí, se deberá hacer mínimo la siguiente
expresión:
∅ = ∑ ∑(𝑦𝑗 − 𝑦𝑡𝑗) 𝑛𝑖𝑗 = ∑ ∑ (𝑦𝑗 − 𝑓 𝑥𝑖; 𝑎1𝑎2 … 𝑎𝑛 )
𝑛𝑖𝑗
𝑖 𝑗 𝑖 𝑗
Al ser los valores
teóricos los obtenidos a partir de la función ajustada.
Para hallar de forma
única los parámetros a1…an que minimizan ∅, la condición necesaria es que las primeras derivadas parciales respecto a cada uno de los
parámetros se anulen.
|
𝜕∅ = 2 ∑𝑖 ∑𝑗 (𝑦𝑗 − 𝑓(𝑥𝑖; 𝑎1𝑎2 … 𝑎𝑛))
1
|
𝜕∅ = 2 ∑𝑖 ∑𝑗 (𝑦𝑗 − 𝑓(𝑥𝑖; 𝑎1𝑎2 … 𝑎𝑛))
2
𝑛𝑖𝑗(-f’a1) = 0
𝑛𝑖𝑗(-f’a2) = 0
𝜕𝑎𝑛 = 2 ∑𝑖 ∑𝑗 (𝑦𝑗 − 𝑓(𝑥𝑖; 𝑎1𝑎2 … 𝑎𝑛))
𝑛𝑖𝑗(-f’an) = 0
Resolviendo
este sistema de ECUACIONES NORMALES queda determinada la función
correspondiente y los parámetros.
RESUMEN AJUSTE
MÍNIMO CUADRÁTICO:
·
Se elige una función de ajuste y=f(x, a1 , a2 ,…, an), donde intervienen n parámetros (a1 , a2 ,…, an),.
·
Tenemos que y=f(x, a1 , a2 ,…, an) es el valor
observado, e y*=f(xi, a1 , a2 ,…, an)
es el valor
teórico que se obtiene a partir de la curva ajustada.
·
Siendo (y-y*)=e (residuo o error).
·
El objetivo es minimizar la suma de los residuos al cuadrado
para obtener los n parámetros (a1 , a2 ,…, an).
|

TIPOS DE AJUSTE
o
Ajuste a una recta: y=a+bx (los resultados son los de
regresión lineal).
o
Ajuste a una parábola: y=a+bx+cx2
o
Ajuste hiperbólico: y=a+b(1/x)
(se utiliza z=(1/x) y se aplica regresión
lineal).
o
Ajuste potencial: y=axb (tomando
log en la ecuación, entonces se aplica un ajuste lineal y se obtienen los
resultados aplicando a los parámetros el antilog).
o
Ajuste exponencial: y=abx (tomando log en la ecuación, entonces se aplica un
ajuste lineal y se obtienen los resultados aplicando a los parámetros el antilog).
El fin es encontrar relaciones entre las variables (sucesos
a investigar). El investigador intenta traducir esas relaciones en estructuras
más manejables, es decir, intenta modelizar esas relaciones funcionalmente a
través de un análisis fundamentalmente estadístico (establece relaciones funcionales en donde un número
finito de
variables X1,…., Xk se supone que están
relacionadas con una variable Y a través de la expresión Y=f(X1….Xk).
Desde este punto
de partida, hay 2 enfoques
con que abordar
simultáneamente este tema:
1.- Teoría de la CORRELACIÓN (apartado 5.3): estudia el
grado de dependencia existente entre las variables.
2.- REGRESIÓN: busca
determinar la estructura de dependencia – modelización- que mejor explique el comportamiento de
la variable Y (variable DEPENDIENTE o EXPLICADA) en función del conjunto de
variables X1....Xk (variables INDEPENDIENTES O EXPLICATIVAS), con las que se supone está relacionada.
Sean X e Y 2
variables cuya distribución conjunta de frecuencias (Xi Yj, nij). Llamamos Regresión
de Y sobre X: a la función que explica la variable y
para cada valor de X , Y=f(X)
Regresión de X sobre Y: comportamiento de
X para cada valor de Y X=f(Y)
Para
la determinación de las funciones de regresión hay dos criterios diferentes:
Regresión I y Regresión II.
REGRESIÓN I:
REGRESIÓN
I DE Y SOBRE X:
Considerando la nube de puntos, si nos preguntásemos cual
sería el valor de Y para X=Xi, existirían varios valores, consideraríamos
que sería la media de las Y cuya X sea X1, es decir, la media
de las Yj cuya abscisa sea X1 (que no es otra cosa que la media de Y
condicionada a que X tome el valor X1, es decir asigna
para cada Xi, un Yj correspondiente a la media
de Y condicionada a X=Xi. Los puntos aparecen
unidos por una línea para indicarnos que son puntos que pertenecen a una misma regresión.
REGRESIÓN I DE X SOBRE
Y: Asigna
para cada Yj, un Xti correspondiente a la media de los Xi condicionados a Y=Yj.
El principal problema
de la Regresión I es que está siempre unida por un conjunto de puntos, y no por una curva continua, lo
cual lo hace poco deseable para nuestro fin fundamental (explicar una variable
a través del comportamiento de la otra). De ahí que se utilice de manera
general el criterio de Regresión tipo II.
REGRESIÓN II: por ajuste
mínimo-cuadrático:
Base: a través de la información suministrada, cuya representación gráfica
es la nube de puntos, 1) se selecciona un tipo de función y posteriormente 2) se ajusta la mejor función de la familia seleccionada
aplicando el método mínimo-cuadrático, es decir minimizando los residuos al cuadrado.
|
Regresión II de Y sobre X: Se trata
de minimizar
COEFICIENTES
REGRESION:
Los coeficientes de regresión lineal
son las pendientes de las rectas
de regresión de Y sobre X.
|
b=Sxy/S2x 𝑏 = tg 𝛼 =
Δ𝑦
El
coeficiente de regresión de Y/X nos mide la tasa de incremento de Y para
variaciones de x, es decir b indica la variación de la variable Y para un
incremento unitario de X.
Análogamente, el coeficiente de
regresión de X sobre Y será b´=Sxy/S2y
Δy
→variación de x correspondiente a un incremento unitario de Y.
Tanto el signo de b
como el de b´será el signo de la covarianza.
Si
Sxy es positiva→b y b´serán
positivos y sus correspondientes rectas de regresión positivas.
Si Sxy es negativa→las 2 rectas de regresión serán decrecientes al serlo sus pendientes.
Si
Sxy es cero→ b y b´=0, es decir
las rectas de regresión serán paralelas a los ejes de coordenadas (y por tanto,
perpendiculares entre sí). Resumiendo:
Los coeficientes de
regresión a y b tienen la siguiente interpretación:
§ El coeficiente “a”
es la ordenada en el origen.
§
El coeficiente “b” es la tangente,
y mide el incremento en Y ante incrementos unitarios en X.
Correlación
Se
llama correlación al grado de dependencia mutua entre las variables. El
problema que se plantea será la medición de la intensidad con que dos variables
pueden estar relacionadas. Para ello recordemos que a través de la función de
ajuste (curva de regresión) expresábamos la estructura de la relación existente
entre las variables y que para cada valor de Xi obteníamos una diferencia llamada residuo, entre el valor de Y en la nube de
puntos y el correspondiente valor teórico obtenido en la función.
Si todos los puntos de la nube estuvieran en la función, la
dependencia sería funcional, y el grado de dependencia sería el máximo posible.
Cuanto más se alejen los puntos de la función (mayores
serán los residuos)
iremos perdiendo intensidad
en la asociación. Esto nos indica a utilizar los residuos para medir la
dependencia y definimos la varianza
residual como la media de todos los residuos elevados al
cuadrado para evitar que se compensen los residuos.
5.5 Mínimos cuadrados
El método de mínimos cuadrados sirve para interpolar valores, dicho en otras palabras, se usa para buscar valores desconocidos usando como referencia otras muestras del mismo evento.
El método consiste en acercar una línea o una curva, según se escoja, lo más posible a los puntos determinados por la coordenadas [x, f(x)], que normalmente corresponden a muestras de algún experimento.
Cabe aclarar que este método, aunque es sencillo de implantar no es del todo preciso, pero si proporciona una interpolación aceptable.
Como se comento previamente se puede usar una recta o una curva como base para calcular nuevos valores.
Sea  un conjunto de n pares con abscisas distintas, y sea
un conjunto de n pares con abscisas distintas, y sea  un conjunto de m funciones linealmente independientes (en un espacio vectorial de funciones), que se llamarán funciones base. Se desea encontrar una función
un conjunto de m funciones linealmente independientes (en un espacio vectorial de funciones), que se llamarán funciones base. Se desea encontrar una función  de dicho espacio, o sea, combinación lineal de las funciones base, tomando por ello la forma:
de dicho espacio, o sea, combinación lineal de las funciones base, tomando por ello la forma:
un conjunto de n pares con abscisas distintas, y sea un conjunto de m funciones linealmente independientes (en un espacio vectorial de funciones), que se llamarán funciones base. Se desea encontrar una función de dicho espacio, o sea, combinación lineal de las funciones base, tomando por ello la forma: .
.Ello equivale por tanto a hallar los m coeficientes:
 . En concreto, se desea que tal función sea la mejor aproximación a los n pares
. En concreto, se desea que tal función sea la mejor aproximación a los n pares  empleando, como criterio de "mejor", el criterio del mínimo error cuadrático medio de la función con respecto a los puntos .
empleando, como criterio de "mejor", el criterio del mínimo error cuadrático medio de la función con respecto a los puntos .
El error cuadrático medio será para tal caso:

Minimizar el error cuadrático medio es equivalente a minimizar el error cuadrático, definido como el radicando del error cuadrático medio, esto es:

Así, los  que minimizan
que minimizan  también minimizan
también minimizan  , y podrán ser calculados derivando e igualando a cero este último:
, y podrán ser calculados derivando e igualando a cero este último:
que minimizan también minimizan , y podrán ser calculados derivando e igualando a cero este último: Siendo i=1, 2, . . ., m
Siendo i=1, 2, . . ., m
Se obtiene un sistema de m ecuaciones con m incógnitas, que recibe el nombre de "Ecuaciones Normales de Gauss". Operando con ellas:
 para i=1, 2, . . ., m
para i=1, 2, . . ., m para i=1, 2, . . ., m
para i=1, 2, . . ., mSi se desarrolla la suma, se visualiza la ecuación "i-ésima" del sistema de m ecuaciones normales:

para cada i=1, 2, . . ., m
Lo cual, en forma matricial, se expresa como:
Lo cual, en forma matricial, se expresa como:

Siendo  el producto escalar discreto, definido para dos funciones dadas h(x) y g(x) como:
el producto escalar discreto, definido para dos funciones dadas h(x) y g(x) como:
el producto escalar discreto, definido para dos funciones dadas h(x) y g(x) como:
y para una función h(x) y vector cualquiera u, como:

La resolución de dicho sistema permite obtener, para cualquier base de funciones derivables localmente, la función f(x) que sea mejor aproximación mínimo cuadrática al conjunto de puntos antes mencionado. La solución es óptima –esto es, proporciona la mejor aproximación siguiendo el criterio de mínimo error cuadrático–, puesto que se obtiene al optimizar el problema.
5.6 Problemas de aplicación
Aplicaciones Ingeniería y Diseño (CAD/CAM, CNC’s) Geología Aeronáutica y automoción Economía Procesamiento de señales e imágenes (Reconocimiento de patrones, recuperación de imágenes) Robótica Medicina (Aparatos auditivos, mapas cerebrales) Meteorología (Mapas climáticos, detección de inundaciones,...) Mundo Virtual Distribuido Multiusuario
En el subcampo matemático del análisis numérico, un spline es una curva diferenciable definida en proporciones mediante polinomios.
En los problemas de interpolación, se utiliza a menudo la interpolación mediante splines porque da lugar a los resultados similares requiriendo solamente el uso de polinomios de bajo grado, evitando así las oscilaciones indeseables en la mayoría de las aplicaciones encontradas al interpolar mediante polinomos de grado elevado.
Para el ajuste de curvas, los splines se utilizan para aproximar formas complicadas. La simplicidad de la representación de curvas en informática particularmente en el terreno de las gráficas del ordenado.
Uno de los principales usos de la interpolación ha sido el hallar valores intermedios a los calculados en tablas trigonométricas, o astronómicas. Tal como dice por ejemplo el anuario del observatorio Astronómico de 2003. Muchas tablas de este anuario contienen listas de valores correspondientes a posiciones dadas para instantes de tiempos sucesivos de una duración de un día. Por medio de la interpolación es posible determinar los valores de tales magnitudes para instantes intermedios a los que aparecen en la tabla.
No hay comentarios.:
Publicar un comentario