Los métodos numéricos para ecuaciones diferenciales ordinarias son procedimientos utilizados para encontrar aproximaciones numericas a las soluciones de ecuaciones diferenciales ordinarias (EDO). Su uso también se conoce como integración numérica, aunque este término a veces se toma para significar el cálculo de una integración.
Muchas ecuaciones diferenciales no pueden resolverse usando funciones típicas ("análisis"). Sin embargo, a efectos prácticos, como en ingeniería, una aproximación numérica a la solución suele ser suficiente. Los algoritmos estudiados aquí pueden usarse para calcular tal aproximación. Un método alternativo es utilizar técnicas de cálculo infinitesimal para obtener una expansión en serie de la solución.
Las ecuaciones diferenciales ordinarias se presentan en muchas disciplinas científicas, por ejemplo, en física, química, biología y economía. Además, algunos métodos en ecuaciones diferenciales parciales numéricas convierten una ecuación diferencial parcial en una ecuación diferencial ordinaria, que luego debe resolverse
Los métodos de un paso tienen por objetivo obtener una aproximación de la solución de un problema bien planteado de valor inicial en cada punto de la malla, basándose en el resultado obtenido para el punto anterior.
Método de Euler:
Desde cualquier punto de una curva, se puede encontrar una aproximación de otro punto cercano en la curva moviéndose una corta distancia sobre una línea tangente a la curva.
Comenzando con la ecuación diferencial (1), se reemplaza la derivada y' por la aproximación respecto a una diferencia finita

que cuando se reorganiza produce la siguiente fórmula

y usando (1) da:

Esta fórmula generalmente se aplica de la manera que se explica a continuación.
Se elige el tamaño de paso h y se construye la secuencia t0, t1 = t0 + h, t2 = t0 + 2h, ... Denotando por yn una estimación numérica de la solución exacta y(tn).
De acuerdo con (3), se calculan estas estimaciones mediante el siguiente esquema recursivo: Este es el método de Euler (en contraste con el método de Euler hacia atrás, que se describe a continuación). El método lleva el nombre de Leonhard Euler que lo describió en 1768.

Es un ejemplo de un método explícito. Esto significa que el nuevo valor yn+1 se define en términos de datos que ya se conocen, como yn.
Método de Taylor:
El método de las series de Taylor para obtener soluciones numéricas de las
ecuaciones diferenciales, consiste en calcular las derivadas sucesivas de la ecuación
diferencial dada, evaluando las derivadas en el punto inicial 0 x y reemplazando el
resultado en la serie de Taylor. La principal dificultad de este método es el cálculo
recurrente de las derivadas de orden superior.
Métodos de Runge Kutta:
Los métodos de Runge-Kutta son una serie de métodos numéricos para resolver ecuandiones ddiferenciales (o bien sistemas de ecuaciones difereneciales).
Son métodos numéticos en los cuales para avanzar al paso siguiente, solo es necesario la información del paso inmediatamente anterior, es decir para avanzar al paso n+1 solo es necesario la información sobre el paso n. O más formalmente
donde es un vector de Rn, >es la variable (real) independiente, h el tamaño del paso, y F es una función vectorial de xn, tn, h, es decir
Obsérvar que este es en realidad un sistema de ecuaciones.
Hay otros métodos llamados multipaso, en los que pasa avanzar al paso siguiente son necesarios dos o más pasos anteriores no los trataremos aquí. También hay otros métodos no lineales, tampoco los discutiremos aquí
donde es un vector de Rn, >es la variable (real) independiente, h el tamaño del paso, y F es una función vectorial de xn, tn, h, es decir
Obsérvar que este es en realidad un sistema de ecuaciones.
Hay otros métodos llamados multipaso, en los que pasa avanzar al paso siguiente son necesarios dos o más pasos anteriores no los trataremos aquí. También hay otros métodos no lineales, tampoco los discutiremos aquí
Teoría en extensión
Los métodos de Runge-Kutta methods son un caso particular (o una especialización) de los métodos numéricos a un paso. Lo que caracteriza a un método de Runge-Kutta es que el error tiene la forma
Donde C es una constante real positiva, el número k es llamado orden del método
El número de etapas del método Runge-Kutta es el número de veces que se evalúa la función en cada paso i, este concepto es importante porque la evaluación de la función requiere un costo computacional (a veces mayor) por eso, son preferidos métodos con un número tan mínimo de etapas como sea posible
Donde C es una constante real positiva, el número k es llamado orden del método
El número de etapas del método Runge-Kutta es el número de veces que se evalúa la función en cada paso i, este concepto es importante porque la evaluación de la función requiere un costo computacional (a veces mayor) por eso, son preferidos métodos con un número tan mínimo de etapas como sea posible
6.2 Método de pasos múltiples.
Los métodos de un paso descritos en las secciones anteriores utilizan información en un solo punto xi para predecir un valor de la variable dependiente yi+1 en un punto futuro xi+1. Procedimientos alternativos, llamados métodos multipaso, se basan en el conocimiento de que una vez empezado el cálculo, se tiene información valiosa de los puntos anteriores y esta a nuestra disposición. La curvatura de las líneas que conectan esos valores previos proporciona información con respecto a la trayectoria de la solución. Los métodos multipaso que exploraremos aprovechan esta información para resolver las EDO. Antes de describir las versiones de orden superior, presentaremos un método simple de segundo orden que sirve para demostrar las características generales de los procedimientos multipaso.


Observe la ecuación ec. 2 alcanza ) a expensas de emplear un tamaño de paso mas grande, 2h. Además, observe que la ecuación ec. 1 no es de autoinicio, ya que involucra un valor previo de la variable dependiente yi-1. Tal valor podria no estar disponible en un problema común de valor inicial. A causa de ello, las ecuaciones 26.11 y 26.12 son llamadas método de Heun de no autoinició.
Como se ilustra en la figura 26.4, la derivada estimada de la ecuación 26.12 se localiza ahora en el punto medio mas que al inicio del intervalo sobre el cual se hace la predicción. Como se demostrara después, esta ubicación centrada mejora el error del predictor a Sin embargo, antes de proceder a una deducción formal del método de Heun de no autoinicio, resumiremos el método y lo expresaremos usando una nomenclatura ligeramente modificada:

6.3 Sistemas de ecuaciones diferenciales ordinarias :
En la primera parte desarrollaremos el estudio de las llamadas ecuaciones
diferenciales ordinarias (EDO) en las que x es una variable escalar, aunque u
puede ser un vector. El orden de una ecuación es el de la derivada que lo tiene
máximo. Así por ejemplo, la ecuación:
y' = y
es una ecuación de primer orden en la que la función incógnita es y, la variable
independiente es x, que no aparece en la ecuación, y donde:
y' = dy/ dx
El teorema fundamental del c´alculo permite obtener la soluci´on de ecuaciones
diferenciales que se encuentran reducidas a cuadraturas, es decir aquellas como:
y' = f(x)
en las que todas las soluciones son simplemente:
y(x) =
f + C
donde el signo integral se refiere a la integral indefinida de f y C es una constante
arbitraria. Sin embargo, en el ejemplo anterior, y'= y, la soluci´on no es tan
trivial. De hecho, se puede interpretar esa ecuaci´on, junto con una condici´on
adecuada, como la definici´on de la funci´on exponencial. En efecto, si se supone
que se busca una soluci´on que verifique y(0) = 1, se encuentra como ´unica
soluci´on:
y(x) = ex.
Todas las soluciones de esta ecuaci´on tienen la forma:
y(x) = Cex
A diferencia de las ecuaciones diferenciales estudiadas en los temas anteriores, consideremos ahora la situaci´on en la que disponemos de una variable independiente t y dos o m´as
variables dependientes: x = x(t), y = y(t), . . .. En el caso de simplemente dos variables
dependientes, y denotando x
0 =
dx
dt , y
0 =
dy
dt , un sistema de ecuaciones diferenciales
ordinarias de primer orden ser´a un sistema de la forma:
x
0
(t) = f(x, y, t)
y
0
(t) = g(x, y, t)
)
En este sistema (6.1) aparecen despejadas las derivadas primeras, cada una de ellas en
una ecuaci´on, denominaremos a esta situaci´on como forma normal de escribir el sistema
(a semejanza de la forma normal para simplemente una ecuaci´on).
Para el caso general, con ecuaciones de orden superior al primero, tendremos que
un sistema de dos ecuaciones diferenciales ordinarias es toda pareja de ecuaciones de la
forma:

6.4 Aplicaciones :
En distintas ramas de la ingeniería se han encontrado aplicaciones de los sistemas de ecuaciones lineales, además de que han abarcado innumerables áreas como la economía y manufactura, por mencionar algunas.
Un sistema de ecuaciones lineales puede utilizarse para representar problemas del mundo real. Cuando hay dos variables y le dan dos datos acerca de cómo se relacionan esas variables, se utiliza un sistema de ecuaciones.
Algunos ejemplos de las aplicaciones de los sistemas de ecuaciones diferenciales son:
º Fracciones parciales
º Determinación de curvas
º Balanceo de reacciones químicas
º Aplicaciones a manufactura
º Transferencia de calor
º Splines Cúbicos
º Problemas de construcción
º Diseño
º Software
º Problemas de circuitos eléctricos (Kirchhoff )
Una técnica muy conveniente utilizada en algunas tareas matemáticas es aquella conocida como fracciones
parciales. Esta se aplica para simplificar integrales o transformadas de Laplace, por citar algunos ejemplos. La ´
idea principal consiste en cambiar la forma que puede ser expresado un cociente entre polinomios a otra forma
m´as conveniente para cierto tipo de calculo.
Una aplicación sencilla de los sistemas de ecuaciones se da en el balanceo de reacciones químicas. La problemática consiste en determinar el numero entero de moléculas que intervienen en una reacción química cuidando siempre que el numero de átomos de cada sustancia se preserve.



















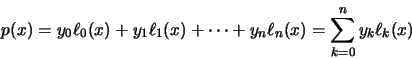
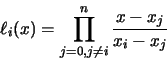
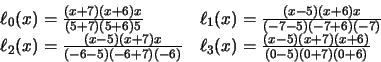










 que minimizan
que minimizan  también minimizan
también minimizan  , y podrán ser calculados derivando e igualando a cero este último:
, y podrán ser calculados derivando e igualando a cero este último: Siendo i=1, 2, . . ., m
Siendo i=1, 2, . . ., m
 para i=1, 2, . . ., m
para i=1, 2, . . ., m

 el producto escalar discreto, definido para dos funciones dadas h(x) y g(x) como:
el producto escalar discreto, definido para dos funciones dadas h(x) y g(x) como:
